基于阿里云 E-MapReduce 、OSS 、边缘网络加速等产品及服务,帮助自建 Hadoop 用户快速构建云上半托管开源大数据平台,在保持原自建 Hadoop 组件使用习惯延续的同时,充分利用云上服务特点,更加便捷地迭代企业大数据平台架构,聚焦业务价值开发。
方案架构
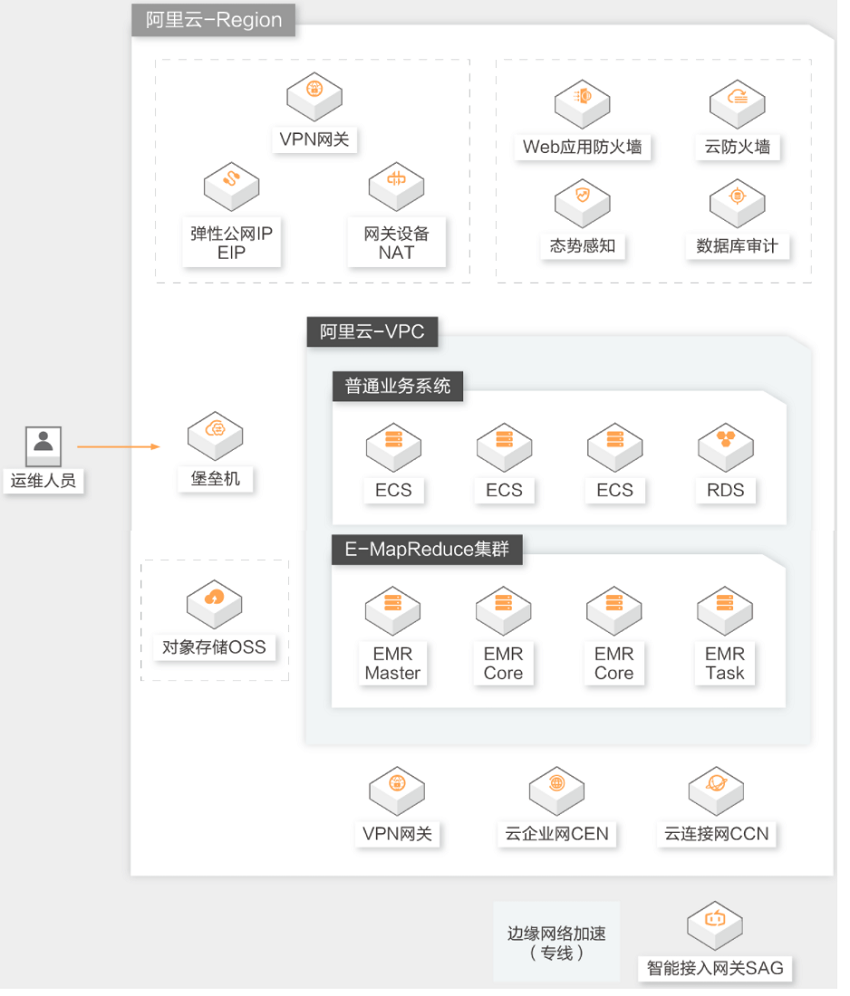
中小企业自建Hadoop集群上云解决方案
本方案核心产品延续开源大数据社区技术栈,提供经过兼容性和稳定性验证的 EMR 和相应组件版本,能够根据业务需求和技术路线,灵活链接阿里云生态和开源大数据生态。
方案能力
降低集群组件兼容性、可靠性验证成本,减轻运维压力
提供基于云服务的扩容和弹性伸缩能力
快速构建存算分离、冷热分层架构
架构优势
功能全面: 覆盖并跟进迭代社区的大部分组件
扩展灵活:充分利用云服务特点,即开即用
生态丰富:支持快速演进到云原生湖仓一体架构
方案优势
开源生态,性能优化
提供高性能、稳定版本 Hadoop 、Spark 、Hive 、Flink 、Kafka 、Hbase 、Presto 、Impala 、Hudi 、ClickHouse 等开源大数据组件,可根据场景灵活搭配使用。采用 JindoFS+OSS ,在保证数据可靠性的基础上,性能大幅提升。
便捷运维,成本节约
分钟级创建集群,支持对集群、节点和服务进行监控和运维操作,大幅提升运维工作效率,让数据工程师更专注于业务开发。集群资源可自动按需匹配,节省计算成本,支持阿里云抢占式实例和存算分离架构,可按冷热数据分层,降低存储成本。
弹性资源,安全可靠
可根据业务场景灵活配置规则,实现弹性伸缩,高效响应快速变化的业务需求。支持 ECS/ACK 形态,可以通过 VPC 和安全组设置集群整体网络安全策略,支持 Kerberos 身份认证、数据加密、Ranger 数据访问控制等安全特性。
应用场景
云原生数据湖
随着企业积累数据规模的增长,数据分析使用往往会遇到数据存储的成本挑战、计算和存储耦合带来的某项资源闲置等问题,同时由于数据分析场景的多样化,如离线计算、流式计算、交互式分析、机器学习等,导致多引擎间频繁地引用和移动数据,造成数据不一致和成本高的问题。通过该方案,可以有效解决以上问题。
流式数据处理
企业对数据的处理,往往同时存在需要批量处理和流式处理的不同环节。本方案构建了安全的数据传输网络,基于 Apache Flink 官方产品Ververica,提供可选的实时计算平台半托管服务,在兼容开源 Flink 的基础上提供商业增值能力,可广泛用于实时 ETL 、数据库 CDC 、实时风控、实时入仓(湖)、实时机器学习等流式数据处理场景。
多样化 OLAP 查询分析
OLAP 查询面向各类业务角色,同时依赖各种异构系统的数据源,需求多样且数据类型复杂,因此发展出了不同的处理系统,用于响应多样化需求。该方案基于E-MapReduce服务,可结合使用习惯按需选择 ClickHouse、StarRocks、Presto、Impala、Druid 等模块并快速开通,用于支持即席查询、固化查询、宽表加速等场景,提升业务决策效率。
使用流程
提交咨询
向阿里云提交方案详情咨询。
初步洽谈
售前技术专家对接,评估需求。
深度洽谈
需求沟通明确,阿里云架构师及专业服务团队为您定制解决方案。
商务流程
为您的解决方案配置专属服务团队进一步洽谈合作。

