

苏州奥尔马电子科技有限公司
江苏省苏州市高新区金猫路9号B幢
丁经理
13584892482
13584892482
135848924828
方案架构
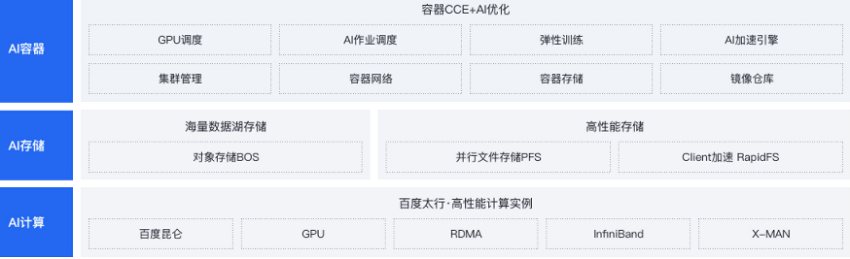
三大核心产品
AI计算
概述
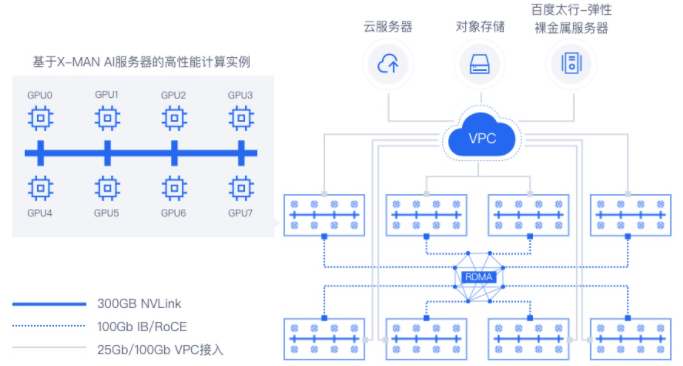
百度太行提供了基于自研GPU硬件架构X-MAN的高性能实例,充分满足AI单机训练、分布式集群训练、AI推理部署等对算、存、传的性能诉求。
能力描述
- 异构计算 : 支持百度自研昆仑AI芯片,多规格商业GPU、FPGA。
- X-MAN AI超级服务器 : GPU多卡NVLink互联,集群RDMA网络通信。
- 百度太行弹性裸金属:统一计算架构,云产品无缝接入,性能零损耗。
AI存储
概述
百度沧海是百度智能云的存储产品体系,基于AI存储架构,从数据上云、数据存储、数据处理和数据加速为计算提供全链条的支撑。
能力描述
- 高效管理 : 5级存储+最全生命周期,统一数据湖、智能生命周期管理。
- 海量高性能 : 统一海量数据平台,高性能存储、高速缓存极致性能。
- 智能处理 : 三大类30+种智能处理能力,存算一体为数据和业务增效。

AI容器
概述
AI容器提供GPU显存和算力的共享与隔离,集成PaddlePaddle、TensorFlow、Pytorch等主流深度学习框架,支持AI任务编排、管理等。
能力描述
- GPU容器虚拟化 : 提供GPU资源共享、隔离,支持算力、显存编解码。
- AI容器调度 : 支持Gang、Spread、Binpack调度,GPU架构感知调度。
- 加速引擎:支持千卡规模自研通信库;算子加速可提升数倍推理效率。

方案优势
高密度
支持GPU资源共享与隔离、架构感知调度,让容器以更细颗粒度调度使用GPU资源,提升异构资源的容器化部署密度,提升资源利用率。
良好易用性
内置PaddlePaddle、TensorFlow、Pytorch等多种主流深度学习框架,满足不同使用需求和习惯。
多场景部署
可根据业务需求在不同场景部署落地,公有云、IDC等场景均可输出AI异构计算平台的解决方案。
乐高式拼接
AI计算、AI存储、AI容器三大核心产品均可各自独立提供服务,并能够无缝兼容存量的基础设施。
应用场景
解决方案
1. 裸金属服务器BBC:自研GPU硬件架构X-MAN的高性能实例(NVLink互联、RDMA网络等),提供超强算力
2. 并行文件存储PFS:并行文件系统提供全闪,RDMA网络为分布式训练提供高性能缓存
3. 容器引擎CCE(AI容器):支持GPU架构感知、 AI框架作业编排,集成TensorFlow、PaddlePaddle等多种主流深度学习框架
4. PaddlePaddle :推荐场景下,支持PaddleREC、Fleet等开源开发套件
业务价值:
1. 相比于CPU训练集群,性价比提升5~40倍
2. 多个模型,CTR提升显著
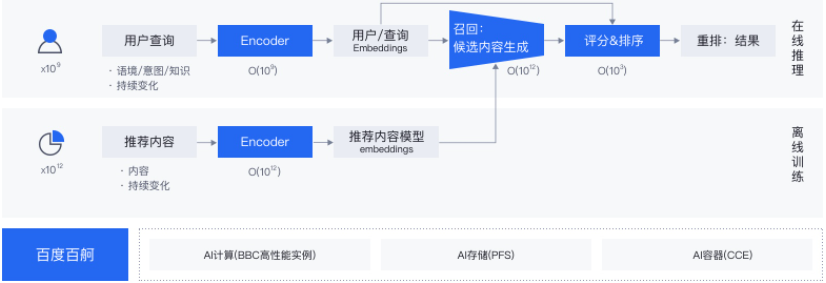
场景描述
无人驾驶训练包括感知、决策规划、定位等场景,其中感知场景GPU使用量较多,感知场景的点云与CV场景模型结构本身比较简单,但有千万到亿条海量训练数据,需要数据并行训练。感知环节输出样本,输入给预测+决策模型进行训练
解决方案
1. 裸金属服务器BBC:自研GPU硬件架构X-MAN的高性能实例(NVLink互联、RDMA网络等),提供超强算力
2. 并行文件存储PFS:并行文件系统提供全闪,RDMA网络为分布式训练提供高性能缓存
3. 容器引擎CCE(AI容器):支持GPU架构感知、 AI框架作业编排,集成TensorFlow、PaddlePaddle等多种主流深度学习框架。小模型和开发机训练场景可使用GPU资源共享提升单GPU的容器化部署密度
业务价值:
1. GPU资源利用率提升50%以上
2. 极大减少自建基础设施维护成本
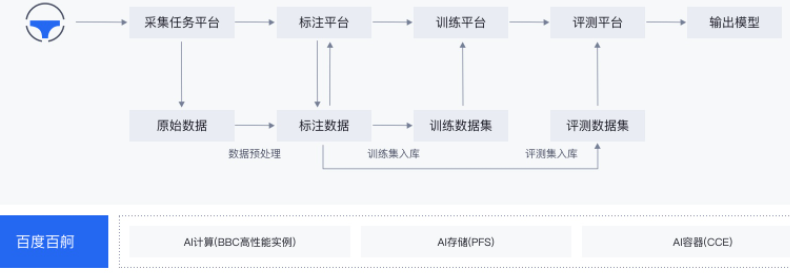
相关产品